





【IJTCS 2020】青年博士论坛精彩回顾
首届国际理论计算机联合大会(International Joint Conference on Theoretical Computer Science,IJTCS)于2020年8月17日-22日在线上举行,主题为“理论计算机科学领域的最新进展与焦点问题”,由北京大学与中国工业与应用数学学会(CSIAM)、中国计算机学会(CCF)、国际计算机学会中国委员会(ACM China Council)联合主办,排列三走势图承办。
8月17-20日,大会“青年博士论坛”如期举行,华为计算理论实验室肖涛博士主持。小编为大家带来论坛精彩回顾。
Reinforcement Learning with Function Approximation: Provably Efficient Algorithms and Hardness Results
王若松,Carnegie Mellon University
讲者首先简单介绍了经典的基于的马尔可夫决策过程 (MDP)以及 Bellman 方程的强化学习模型框架。对于有限的状态集合 S,行动集合 V 还有有限的终止步数 H,训练需要的复杂度为 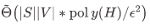 ,其中
,其中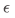 为目标误差。然而某些问题中状态集合 S 是指数级大的,例如围棋游戏中,
为目标误差。然而某些问题中状态集合 S 是指数级大的,例如围棋游戏中,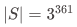 ,完全不可接受。
,完全不可接受。
因此实际应用中常使用的方式是利用函数近似,例如用神经网络来近似 Q 函数。那么一个基本的问题是,假设使用的函数近似方式可以达到近似完美的近似效果,那么此时能否有高效训练算法。讲者及其合作者证明了无论采用 Value-based 还是 Policy-based 的训练方式,对于线性特征映射,核函数以及神经网络等函数类,都存在一类困难的 MDP,使得0.25近似也需要指数级的复杂度。
在说明假如想实现高效的强化学习,还需要加入更强的理论假设之后。讲者及其合作者增加的假设为:对于任意属于近似函数类 F 的近似函数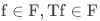 ,其中 T 为 Bellman Operator。并在这一假设下设计了 F_LSVI 算法。该算法通过加入一个奖励项,最终实现了在一般的函数类上,也可在多项式的复杂度内训练完成。
,其中 T 为 Bellman Operator。并在这一假设下设计了 F_LSVI 算法。该算法通过加入一个奖励项,最终实现了在一般的函数类上,也可在多项式的复杂度内训练完成。
讲者最后简单总结了上述的困难性与算法结果,并指出了三个下一步需要研究的问题:
1. 若抛弃“函数近似方式可以达到近似完美的近似效果”这一假设,会得到怎样的理论结果;
2. 能否将 Eluder dimension 应用于分析更多实践中使用的函数类,例如核函数,神经网络等;
3. 能否找到除 Eluder dimension 外更好的对于使用函数近似的强化学习的复杂性的度量。

Why Are Convolutional Nets More Sample-Efficient than Fully-Connected Nets?
李志远,Princeton University
在机器学习技术中,人们通常认为卷积神经网络相比于全连接神经网络拥有更好的泛化性,尤其是在图像分类任务上有着明显的优势。然而,在理论上对于同一训练任务,全连接网络始终可以完全模拟出卷积神经网络,因此如何理解并从数学上证明卷积神经网络的优势始终是一个未解难题。
在本篇文章中,作者从样本复杂度入手对这一难题进行了阐释。所谓训练算法的样本复杂度是指将算法错误率降低到一定程度所需的最小样本数量。作者首先引入了等变算法的概念,可以将不同的训练算法进行对比和转化,并能够以这种方式给出训练算法样本复杂度的下限。同时,作者证明了全连接神经网络中许多训练算法的等变性,并总结了判断等变算法所需的一些充分条件。最后,作者还用递归的方法给出了一些算法的样本复杂度下限。需要注意的是,卷积神经网络中的卷积层和池化层突破了等变算法的判断条件,因此可以拥有更好的样本复杂度下限,这一定程度上解释了其泛化性更好的特点。

Fast Sampling and Counting K-SAT Solutions in the Local Lemma Regime
凤维明,南京大学
讲者在报告中讨论了 (k,d)-CNF 的满足解的采样与计数问题。(k,d)-CNF 即每个子句中包含 k 个变量,且每个变量最多出现在 d 个子句中的 CNF。对于采样问题,作者们提出了基于马尔可夫链蒙特卡洛(MCMC)的方法。由于可行解的空间是不连通的,普通的 Gibbs 采样无法近似正确的分布。在前人的工作中,基于 MCMC 的方法需要 CNF 是单调的;也有非 MCMC 的方法,但也需要 CNF 满足一些比较严格的性质。在这篇工作中,作者们采用了投影的技术,增加了解集的连通程度,使得 MCMC 方法能够绕过原本不连通的性质。
具体来说,先利用 Morse-Tardos 算法从变量集合中构造一个“好”的子集,再在关于这个子集的边缘分布上进行 Gibbs 采样,得到该子集中变量的赋值,最后对于剩下的变量,从已知“好”子集赋值的条件分布中使用拒绝采样得到赋值。作者们利用 Lovász local lemma 证明了M-T算法以高的概率成功找到“好”子集, Glauber dynamics 在投影后的空间中收敛到正确的边缘分布,且拒绝采样成功,从而算法输出的解的分布近似于均匀分布。另一方面,作者们证明了算法的运行时间关于 k, d 是多项式的,且关于 n(变量个数)几乎是线性的。利用模拟退火法,我们可以通过运行采样算法得到解的计数算法,其运行时间关于 n 几乎是平方级别的。

Lovasz Local Lemma: Variable and Quantum
何昆,深圳大学
Lovasz 局部引理(LLL)是组合学和概率论中非常强大的工具,它显示了在某些“弱依赖”条件下避免所有“坏”事件的可能性。在过去的几十年中,LLL 的算法,尤其是 variable version of LLL(VLLL),在理论计算机科学界引起了很多关注。最近,Ambainis 等人提出了 quantum version of LLL(QLLL),QLLL 对解决量子可满足性问题有很大的帮助。
作者证明了 VLLL 的紧的界超出了 Shearer 给出的界,并且 Shearer 的界对于 QLLL 是紧的,证实了 Sattath 等人提出的猜想。对于 commuting version of LLL(CLLL),也即 VLLL 和 QLLL 之间的 LLL,作者证明了 CLLL 和 QLLL 的紧区域在总体上是不同的。

Coreset Construction for Clustering
黄棱潇,耶鲁大学
如何将多样的数据进行整理并从中取出代表元素是数据科学中的重要问题,在面对巨量数据时,若能有效的选取代表元,一方面能节省数据储存的开支,另一方面也能更有效地分析数据,在节省时间空间的情况下对于目标问题给出一个合理的近似。而 coreset construction 正是想要提取这样一组代表元。
这样的选取代表元的问题又可以根据衡量差距的度量细分为各种特殊情形,例如经典的 k-means clustering 就可以通过随机初始化和引入权重(重要性采样)来在期望意义下快速得到一个近似最优解。作者通过将数据投影到低纬和重要性采样给出了针对一类更广泛的度量均可以快速运行的算法,并且得到的代表元数据集的大小只与所需要的精度相关,与数据维数和数目无关。
最后,讲者认为未来对于代表元与精度的依赖关系可以进一步改进,而相应的算法也将在神经网络及非凸优化中得到进一步的应用。

Rapid Mixing from Spectral Independence beyond the Boolean Domain
张驰豪,上海交通大学
讲者在报告中介绍了他们关于 spectral independence 的工作。作者们将“布尔取值的概率分布如果 spectrally independent,则对应的 Glauber dynamics 在多项式时间内收敛”这一结论推广到了整数取值上。作为一个例子,讲者展示了对图染色方案均匀采样的 Glauber dynamics,并证明其当颜色数 (其中 是最大度数)且图中没有三角形时在多项式时间内收敛。
在证明中,作者们利用 local to global 的方法,即若局部随机游走的第二大特征值有较小的上界,则能给出全局的 Glauber dynamics 的第二大特征值的上界,从而给出收敛时间的多项式上界。对于局部随机游走的分析,作者们使用了 coupling 的方法证明了局部随机游走快速收敛,从而给出了其第二大特征值的上界。
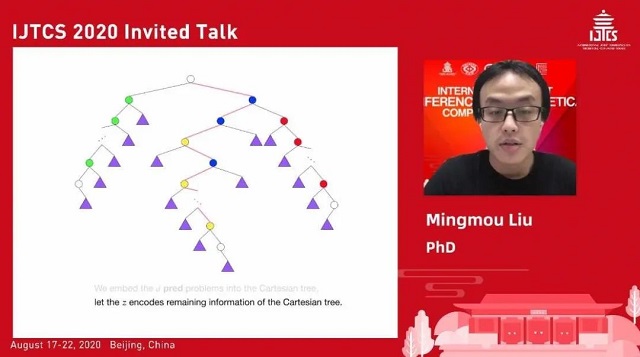
Lower Bound for Succinct Range Minimum Query
刘明谋,南京大学
讲者在报告中介绍了他们的关于区间最小查询(RMQ)问题的空间下界的证明。RMQ 问题是指,给定一个整数数组,每次查询一段区间内的最小值的下标。RMQ 问题在计算机科学领域应用广泛,且与树上的最近公共祖先问题是等价的。目前最好的数据结构,当查询时间是常数时需要使用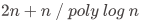 的空间。作者们证明了在常数查询时间下,该数据结构是最优的;一般地,当数据结构的查询时间是
的空间。作者们证明了在常数查询时间下,该数据结构是最优的;一般地,当数据结构的查询时间是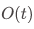 时,至少需要
时,至少需要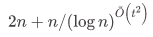 的空间。这里作者采取的计算模型是 cell-probe model,与 RAM model 类似,但只有访问内存花费代价。
的空间。这里作者采取的计算模型是 cell-probe model,与 RAM model 类似,但只有访问内存花费代价。
关于下界的证明,作者们先将 pred-z 规约到 RMQ,并通过证明 pred-z 问题的下界证明 RMQ 的下界。Pred-z 问题是前驱查询的一个变种,给定一系列集合与某个很大的数 z,要求数据结构支持查询某个集合内某个数的前驱与返回 z。后者是为了强制算法浪费空间,因为普通的前驱查询在规约下熵很小,直接对其进行规约会导致很大的冗余。关于 pred-z 下界的证明,作者们利用 round elimination 给出 pred-z 的下界。

Fair Resource Sharing and Dorm Assignment
李博,The Hong Kong Polytechnic University
论文主要研究和推广了资源共享问题(Resource Sharing Problem)。在传统的资源共享问题中,通常假设有多个物品和参与者,其中每个参与者拥有对各个物品的效用偏好,此时要解决的问题即为如何给参与者分配物品以满足公平性的条件。通常来讲,在该问题中以无嫉妒性(envy-freeness)来刻画公平性,即在最优情况下应该没有任何参与者会嫉妒其他参与者获得的物品。
而在本篇论文当中,作者将资源共享问题进行了推广。首先,作者将物品的性质进行了放宽,允许多个人同时分配同一个物品,这可以对应到现实中分配宿舍的类似实例之上。同时作者不仅考虑了单个参与者对物品的偏好,同时还考虑了共享资源产生的外部性,即与不同参与者共享同一物品也有效用差别。之后,作者将无嫉妒性的条件进行了放松,提出了无帕累托嫉妒的性质,即对于任何两个参与者,最多只会嫉妒物品分配效用或共享效用其中之一。作者证明了,当所有物品的共享容量为2时,总存在无帕累托嫉妒的分配,并可以在多项式时间内找到分配方法。而对于共享容量为3或更多时,则无法保证存在无帕累托嫉妒的分配。
Incentive Analysis on Peer-to-Peer Resource Sharing Networks
阎翔,上海交通大学
在本次报告中,讲者介绍了对等网络(Peer-to-Peer Network)中资源共享机制中存在的博弈分析。在对等网络中,每个网络节点是一个智能体(agent),他们将自己冗余的资源分配给相邻的节点,以换取其邻点的资源,这样的资源共享场景构成了一种特殊的线性 Arrow-Debreu 市场,而这一市场的市场均衡可以通过一种“比例反应机制”(proportional response mechanism)得到。讲者首先介绍了这一机制的优点,即使得每个智能体的收益在均衡条件下达到最优,同时保证了不同智能体之间的公平性,但是讲者指出这些优点是建立在所有智能体都诚实的参与资源共享机制这一条件基础上的,因此讲者着重分析了智能体有可能采取的欺骗行为以及相应对机制的影响。
具体来说,讲者共讨论了四种欺骗行为:权重欺骗(某个智能体不将自己所有的资源用于共享)、连接欺骗(某个智能体不与某个特定的邻点进行资源共享)、假名欺骗(某个智能体复制多个网络身份参与资源共享)、女巫攻击欺骗(某个智能体创建多个虚假的身份单独与特定邻点进行资源共享)。借助一种特殊的组合技巧——瓶颈分解,讲者刻画了市场均衡下具体的资源共享形式,进一步通过分析在某个智能体采用某种欺骗策略前后网络的瓶颈分解结果,可以证明智能体无法通过权重欺骗、连接欺骗或假名欺骗获得额外的收益,而通过女巫攻击欺骗,智能体最多只能获得常数倍的额外收益,即智能体通过各种欺骗策略能够获得的收益极为有限。换言之,在这一机制下,智能体没有动力采取欺骗行为,侧面反应了该资源共享机制的稳定性。